

En ingeniería de datos una de las tareas principales es la automatización de transformaciones de datos, normalmente, aplicando la arquitectura de Extracción-Transformación-Carga (ETL). El volumen del conjunto de datos inicial de trabajo puede ser enorme y su tratamiento puede resultar costoso computacionalmente, generando ineficiencias en tiempos de ejecución y computo.
Por este motivo hay una gran preocupación por optimizar los procesos de transformación de datos. Aunque existen diferentes técnicas en las que actuar como vectorizar, el patrón memoización en ingeniería de datos es una de las más efectivas.
Es una técnica de optimización que busca evitar procesamientos que presentan subproblemas solapados y redundantes. Su aplicación consiste en guardar los resultados de operaciones en estructuras de datos adecuadas, facilitando su reutilización en consultas o análisis posteriores sin necesidad de recalcularlos, disminuyendo así la carga computacional y el tiempo de procesamiento.
Aunque la técnica es relativamente sencilla, puede ser aplicada de diferentes formas por los equipos de ingeniería de datos. A continuación presento dos casos prácticos en los que puedes aplicar esta técnica para optimizar: Una para consulta y otra para el cálculo de datos.
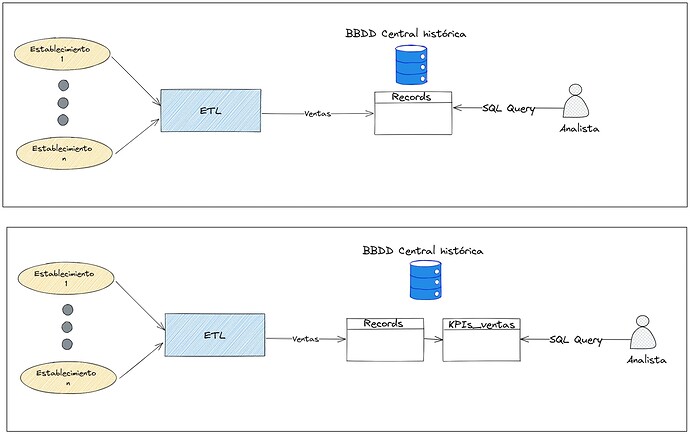
Imaginemos que estamos un negocio de retail y tenemos que procesar los datos de varios establecimientos. Por ejemplo, los artículos vendidos y su importe. Se nos pide que calculemos de forma automatizada las ventas producidas y así poder consultar cómo va el negocio con KPIs (indicadores clave de rendimiento) tales como las ventas totales por provincia.
Una de las formas más prácticas es persistir las ventas de forma centralizada para que, una vez tengamos esto calculado, simplemente persistir los datos en nuestras bases de datos para que pueda ser consultado y calculado por los analistas de datos. Sin embargo, este tipo de soluciones deben de realizar consultas complejas y pesadas por el gran número de registros por establecimiento y la cantidad de estos. Pueden existir ineficiencias en tiempos de ejecución y computo cuando se realizan los agrupados para poder obtener los cálculos por provincias. Este problema se agrava ya que se repite con cada actualización de datos. La lentitud en tener los datos disponibles era una de las fuentes de quejas de los analistas de datos.
Para resolver el problema, podemos aplicar la memoización creando una tabla intermedia llamada, por ejemplo, “KPIs_ventas”, que almacene los resultados de estos cálculos. Cada vez que se requieran estos KPIs, en lugar de ejecutar nuevamente las consultas complejas, se consultará esta tabla para obtener los valores ya calculados, minimizando así la carga computacional y el tiempo de procesamiento asociados. Además, esta tabla intermedia puede actualizarse periódicamente con procesos batch (por ejemplo, al final de cada día) mediante la ejecución de las consultas necesarias para incorporar nuevos datos. De esta forma mantenemos la información actualizada, relevante al mismo tiempo que automatiza la labor de los analistas permitiéndoles acceder de manera rápida y eficiente a los datos ya procesados. Consecuentemente, esta estrategia facilita la reutilización de los resultados en otros análisis o reportes, mejorando sensiblemente la toma de decisiones y la planificación de estrategias comerciales.
En este segundo caso práctico trataremos la transformación de datos heterogéneos que van a ser utilizados de forma conjunta. Pongámonos en el ejemplo de una organización supranacional que necesita calcular el impacto energético y medioambiental de una serie de empresas. El objetivo es evaluar si las medidas implementadas para incentivar la eficiencia energética están teniendo efecto. Para ello, como punto de entrada del estudio, deberemos extraer la información necesaria con fuentes de datos de varios proveedores. Además, para poder hacer comparativas por sectores/industrias es necesario estandarizar los resultados, con el fin de tener valores comparables. Podríamos aplicar la siguiente estrategia para resolver el proyecto:
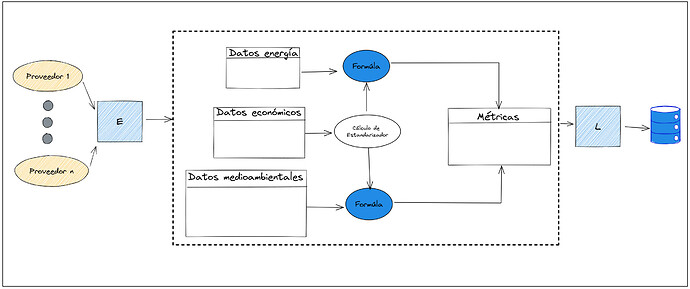
Esta solución tiene un problema, por cada métrica de energía o medioambiental a calcular hay que obtener también esta variable estándarizadora, por ejemplo, utilizando valores económicos de la empresa, cómo medida del tamaño y actividad (unidades de metrica / millones de euros o dolares). Este simple cálculo, que inicialmente parece no impactar al tiempo de proceso, es una subtarea redundante cuyo impacto se traduce en una explosión combinatoria igual a organizaciones^(metricas-1) dentro del proceso de cálculo.
Con el fin de optimizar este proceso podemos aplicar la estrategia de memoización guardando en una tabla intermedia el cálculo de esta variable estandarizadora para cada organización. De esta forma, solo tendríamos que ejecutar su cálculo una vez por organización. El planteamiento podría incorporarse al proceso ETL de la siguiente manera:
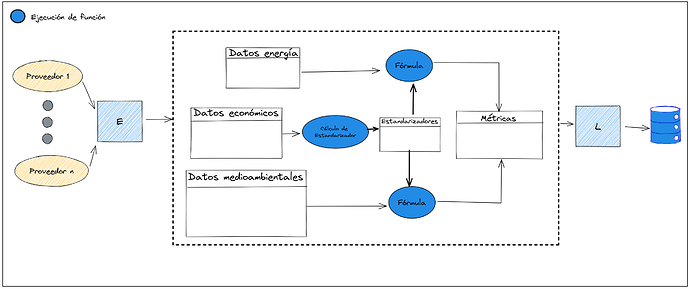
Así tendríamos un proceso más óptimo que adicionalmente generará valor a lo largo del tiempo.
El patrón memoización es imprescindible cuando se trata de procesamiento y tratamiento de datos, siendo más acusada su necesidad a medida que las dimensiones se acercan al Big Data. La complejidad de aplicar esta técnica radica en hacer un buen planteamiento de cómo será el flujo de datos y cómo serán tratados, almacenados o consumidos, así como elegir la estructura de datos o almacenamientos más adecuados. En ese post hemos visto dos ejemplos posibles. Estos manifiestan la necesidad de, no solo es conocer el patrón, sino utilizarlo de forma eficiente con el objetivo de optimizar los procesos de ingeniería de datos.
Este post ha sido posible gracias a Francisco Mesa, Cristian Súarez y Jonay Godoy que en una sesión de formación trabajaron el concepto de la memoización. Esta me sirvió de inspiración para trasladarlo al mundo del Big Data.
Gracias compañeros y a Lean Mind por invertir en Formación!
Una especial mención a Francisco Mesa por su feedback, que ha permitido que este post tenga más calidad gracias a su experiencia.
¿Quieres más? te invitamos a suscribirte a nuestro boletín para avisarte cada vez que recopilemos contenido de calidad que compartir.
Si disfrutas leyendo nuestro blog, ¿imaginas lo divertido que sería trabajar con nosotros? ¿te gustaría?
Pero espera 🖐 que tenemos un conflicto interno. A nosotros las newsletter nos parecen 💩👎👹 Por eso hemos creado la LEAN LISTA, la primera lista zen, disfrutona y que suena a rock y reggaeton del sector de la programación. Todos hemos recibido newsletters por encima de nuestras posibilidades 😅 por eso este es el compromiso de la Lean Lista
