

Recuerdo el primer día, en una sesión de formación de Lean Mind, cuando me enfrenté a este tipo de testing y no supe cómo debía afrontarlo. Luego, en los debates posteriores a la sesión de kata, estuve escuchando varias opiniones sobre lo que se debía hacer. Algunas sonaban incluso contradictorias. Sin embargo, al profundizar en el tema, me di cuenta de que son simplemente enfoques distintos que dependen del contexto y la complejidad de la propiedad a testear; se puede usar una u otra en función de estos factores. Pero antes de continuar, una pregunta importante que deberíamos hacernos es: ¿Qué es una propiedad?
Podemos hacer un paralelismo con la ciencia. Pensemos, por ejemplo, en el agua. ¿Qué la caracteriza? O mejor dicho, ¿cuáles son sus propiedades? Podríamos pensar en su densidad, en que cuando está en estado sólido (hielo) es menos denso que en estado líquido. Tiene conductividad eléctrica, así como el hecho de que está compuesta por dos átomos de hidrógeno y uno de oxígeno. En resumidas cuentas, son cosas que siempre se cumplen. Pues bien, en el software, cuando hablamos de propiedades, nos referimos a aquellas cosas que deben cumplirse siempre para que este se comporte de la manera deseada y necesaria para su uso. Estas cosas pueden ser reglas de negocio (por ejemplo, que los beneficios de una empresa sean la resta de los ingresos y gastos), o hechos que deben cumplirse (como que la nevera inteligente siempre tenga entre 2 y 10 artículos pase lo que pase). Una de estas propiedades por sí sola no asegura nada; es el conjunto de todas estas lo que caracteriza el comportamiento complejo y deseado en un software.
Podemos clasificar las propiedades en dos:
Podemos distinguir al menos dos componentes individuales: el generador y la condición que se debe cumplir siempre. Hagamos un inciso en el generador. ¿Qué es? Podemos describirlo como una función que contiene una gran cantidad de parámetros internos que dirigen su aleatoriedad, como la complejidad de los datos que crea y la información sobre otros generadores que se pueden utilizar como parámetros. Esta es la pieza más importante de una propiedad, porque de ella depende la calidad y la confiabilidad. Normalmente, para cada lenguaje puedes encontrar un framework que suministra esto, y hace posible una sencilla práctica del testing basado en propiedades. Dicho esto, veamos un ejemplo: la siguiente propiedad de la kata Fizzbuzz escrita en C# con FsCheck.
Prop.ForAll<int>(
generatorOfNumbersDivisibleByThree, (int NumbersDivisibleByThree) =>
{
new FizzBuzz().execute(NumbersDivisibleByThree).Should().Be("Fizz");
}
);
En este caso, se ha abstraído el generador en una función para darle mayor legibilidad a la propiedad. Como puede observarse, el generador proporciona una entrada que es un subconjunto de números enteros; en este caso, son números divisibles por tres. Esto se hace porque el software que se desarrollará en la kata tiene la propiedad de transformar todos estos números en el string “Fizz”. Esto, con TDD, también podría estar cubierto. ¿Cuál es la diferencia?
Con TDD, realizamos un testing basado en ejemplos: “Dada una situación inicial / dados unos inputs, nuestro sistema debería hacer o provocar x salida o efectos colaterales”. Esto implícitamente esconde reglas de negocio o hechos que debe cumplir nuestro software (por eso Carlos Blé insiste en hacer esto explícito en los nombres de los tests en su libro “Diseño Ágil con TDD”). Ahora bien, deberíamos cuestionarnos: ¿Con el ejemplo que hemos puesto a prueba, tenemos la confianza de que se cumple esa regla de negocio? La mejor respuesta es: Hasta donde conocemos y sabemos, sí. Tendríamos que pensar en casos límite o combinatorios y exponerlos para saber si nuestro software realmente funciona bien. Por ejemplo, tenemos un algoritmo de ordenamiento sencillo, le pasamos una lista de números y, perfecto, nos la devuelve ordenada, pero ¿qué ocurre si la lista está vacía? ¿Y qué ocurre si la lista contiene números iguales? Probablemente nuestro software falle y hasta que no ocurra el error, no lograremos cubrir esos casos. Vale, es un ejemplo simple, pero pensemos que esto ocurre en sistemas más complejos donde esos ejemplos son sutiles y son combinaciones que no pensamos de antemano. Bueno, ahora te pregunto: ¿Podríamos adelantarnos y encontrar estos bugs en nuestro software durante el desarrollo? Sí, y es por esto que el Property Based Testing es un gran complemento para TDD. Mientras TDD nos permite lograr un software de diseño simple y testable, el Property Based Testing, nos permite adelantarnos a errores, porque pone a prueba nuestro software bajo entradas que seguramente no hubiéramos pensado. ¿Cómo trabajamos con propiedades y cómo las encontramos? Veámoslo.
Cualquiera que sea la técnica que se use, es importante tener presente que si identificar una propiedad se torna complejo, lo mejor que se puede hacer es dividir y vencer, y tener una perspectiva de desarrollo progresivo. Por otro lado, cada técnica exige un nivel de confianza en esas funciones que permiten verificar la propiedad. La cuestión está en tener calculado el riesgo en cada caso, y es un aspecto importante a valorar a la hora de elegir una técnica u otra.
Trabajar con propiedades es un proceso iterativo donde se ejecuta la propiedad contra el código de producción. Siempre que haya un fallo, hay que averiguar:
Aterricemos esto último con el ejemplo anterior de la Kata Fizzbuzz, donde un número divisible por tres debe convertirse en “Fizz”. Si el generador produce un 15, ¿qué está mal? ¿El programa o la propiedad? En este caso, la propiedad. Habría que acotar que no sea divisible por 5. En cualquier otro caso, una vez ajustado esto, si falla, sería un problema del programa seguramente, pero siempre hay que observar y plantear la hipótesis de la propiedad.
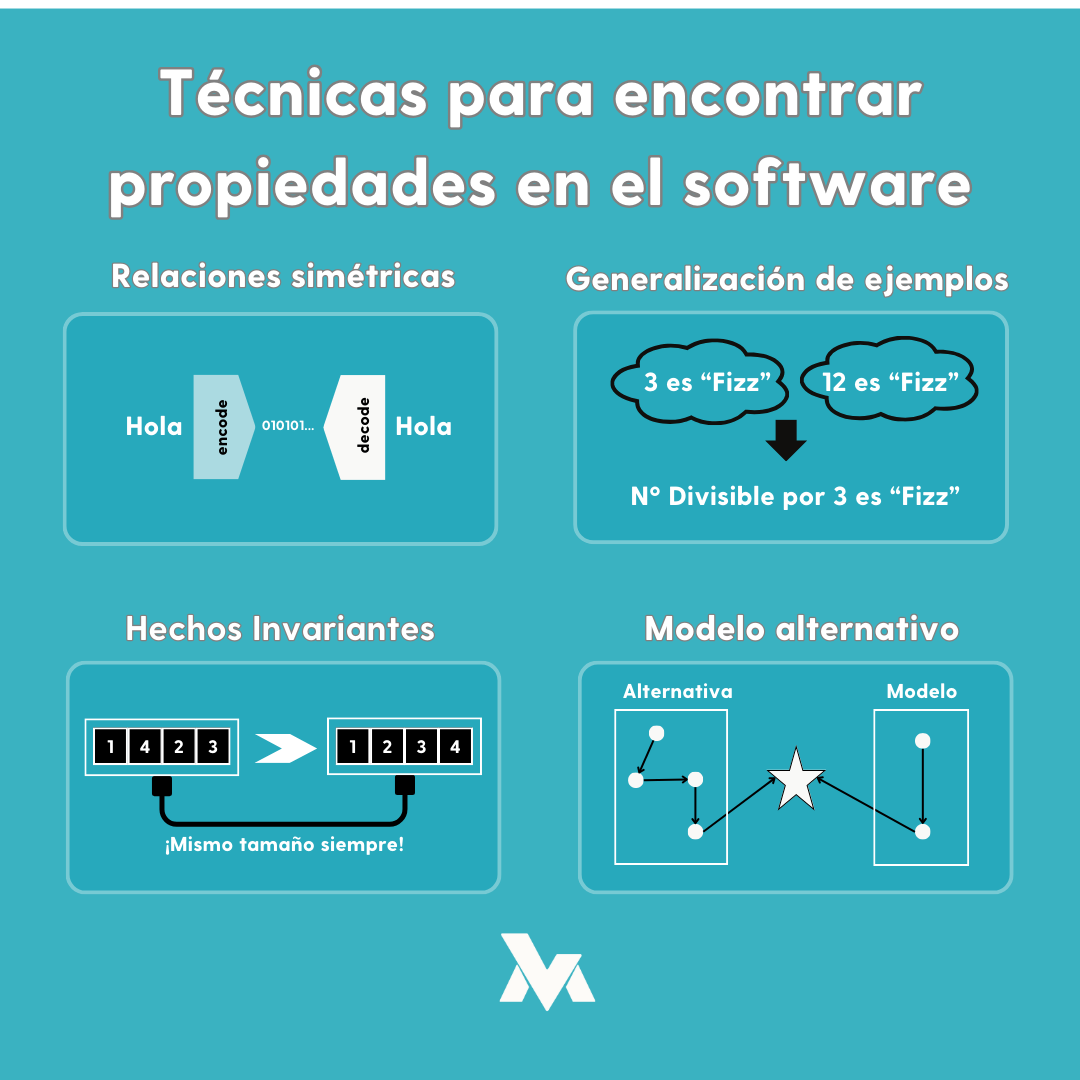
Dicho esto, veamos al menos cuatro posibilidades que podríamos usar:
Se trata de usar un modelo diferente al usado en producción y que, por tanto, resulta normalmente menos eficiente. Su misión es proporcionar una alternativa que produzca un resultado que es obviamente correcto, con el cual comparar. El nivel de confianza en una propiedad creada con este enfoque, será directamente proporcional a la fiabilidad de este modelo alternativo.
Esta técnica se suele usar cuando se dispone de librerías estándar, que resultan más lentas, pero en las que podemos depositar confianza. Por ejemplo, si desarrollamos un algoritmo que busque el número más grande de una lista, podríamos usar un modelo alternativo donde se realice una ordenación y luego se tome el último elemento, mientras que el modelo de producción, realizará una comparación por pares y guardará en memoria el más grande encontrado hasta la última comparación (solución más eficiente en recursos).
Ejemplo en C# con FsCheck:
namespace Kata.biggest_number;
public class BiggestNumber
{
public static int FindBiggestNumber(List<int> numbers)
{
var biggestNumber = numbers[0];
foreach (var number in numbers)
{
if (biggestNumber < number)
{
biggestNumber = number;
}
}
return biggestNumber;
}
}
using FluentAssertions;
using FsCheck;
using FsCheck.Fluent;
using FsCheck.Xunit;
using Kata.biggest_number;
namespace Kata.Tests;
public class BiggestNumberShould
{
[Property]
public Property FindsBiggestNumberWithMaxFunction()
{
var generatorOfListOfNumbers = (
Gen.Choose(int.MinValue, int.MaxValue).NonEmptyListOf().ToArbitrary()
);
return Prop.ForAll(generatorOfListOfNumbers, numbers =>
{
var biggestNumber = BiggestNumber.FindBiggestNumber(numbers);
biggestNumber.Should().Be(numbers.Max());
});
}
[Property]
public Property FindsBiggestNumberWithSortingModel()
{
var generatorOfListOfNumbers = (
Gen.Choose(int.MinValue, int.MaxValue).NonEmptyListOf().ToArbitrary()
);
return Prop.ForAll(generatorOfListOfNumbers, numbers =>
{
var biggestNumber = BiggestNumber.FindBiggestNumber(numbers);
numbers.Sort();
biggestNumber.Should().Be(numbers[^1]);
});
}
}
Esta técnica es útil cuando la complejidad de un componente es baja y, por lo tanto, el modelo será sencillo, así como en pruebas de integración de sistemas, donde se producen muchos efectos colaterales o donde hay varias dependencias. Esto se debe a que, podemos enfocar las pruebas de una manera sencilla desde el punto de vista de lo que percibe el usuario, en lugar de complicarnos con los detalles de cómo se produce la interacción. Podemos pensar en un Fake Object de una base de datos, donde se emulan las operaciones en estructuras de datos sencillas en memoria, eliminando la complejidad de la conexión, autenticación, etc. Hay que prestar atención al rendimiento de las pruebas, dado que los modelos son menos eficientes. Lo positivo es que es la forma más sencilla para empezar a obtener propiedades.
Esta técnica consiste en la sustitución de test desarrollados, con el enfoque basado en ejemplos (por ejemplo aplicando TDD) por generadores. Es decir, se empieza a trabajar con ejemplos, y desde estos es posible identificar un posible generador que los sustituya (cómo si de un test parametrizado se tratara). Con esto, podemos generar propiedades más sencillas y desagregadas. Un ejemplo podría ser una función que nos devuelve el último elemento de una lista, en un test basado en ejemplos, podríamos añadir un elemento conocido a la lista antes de ejecutar la función y nos debería devolver esta. Pues bien, esto sería sencillo de sustituir con generadores para transformarlo en una propiedad:
using FluentAssertions;
using FsCheck;
using FsCheck.Fluent;
using FsCheck.Xunit;
using Kata.biggest_number;
namespace Kata.Tests;
public class LastNumberShould
{
[Fact]
public void PickTheLastNumber__ExampleBased()
{
var knowNumber = 5;
var numbers = new List<int> {1, 2, 3, 4, knowNumber};
var lastNumber = LastNumber.FindLastNumber(numbers);
lastNumber.Should().Be(knowNumber);
}
[Property]
public Property PickTheLastNumber__PropertyBased()
{
var generatorOfListOfNumbers = (
Gen.Choose(int.MinValue, int.MaxValue).NonEmptyListOf().ToArbitrary()
);
var generatorKnownNumbers = (
Gen.Choose(int.MinValue, int.MaxValue).ToArbitrary()
);
return Prop.ForAll(
generatorKnownNumbers,generatorOfListOfNumbers,
(knowNumber, numbers) =>
{
numbers.Add(knowNumber);
var lastNumber = LastNumber.FindLastNumber(numbers);
lastNumber.Should().Be(knowNumber);
});
}
}
namespace Kata.biggest_number;
public class LastNumber
{
public static int FindLastNumber(List<int> numbers)
{
return numbers[^1];
}
}
Consiste en identificar condiciones o hechos atómicos en un sistema de software que deberían cumplirse siempre. Estos, por sí solos, no garantizan que el sistema se comporte como se espera, pero si se identifican varios de estos, se puede ganar una alta confianza. Además de esta atomización, también se puede obtener una alta precisión acerca de por qué el sistema ha dejado de comportarse como se espera.
Una forma de poder llegar a identificar invariantes, es trabajar a partir de una propiedad e intentar dividirla en partes más pequeñas. Pueden ser diferencias sutiles que no impliquen un resultado completo, sino un subresultado. Sin embargo, al ejecutar la propiedad, se acabará comprobando todo el resultado.
Lo positivo de las invariantes es que, una vez identificadas, son fáciles de entender. Por lo general, se validan rápidamente y se combinan bien, por ejemplo, con el testing basado en ejemplos, funcionando como una especie de parametrización.
Lo negativo es que tenemos que confiar en funciones predefinidas del lenguaje, o condicionales (en el caso de JavaScript, esto podría ser un problema serio). En cualquier caso, sería un riesgo calculado.
Un ejemplo sobre el desarrollo de un algoritmo de ordenación. Si pensáramos en hechos que deben ocurrir siempre de forma atómica, podríamos pensar en:
Teniendo estas propiedades, podríamos tener una alta confianza de que el software funciona correctamente.
using Kata.biggest_number;
namespace Kata.Tests;
using FluentAssertions;
using FsCheck;
using FsCheck.Fluent;
using FsCheck.Xunit;
public class ListSorterShould
{
[Property]
public Property ASortedListHasOrderedPairs()
{
var generatorOfListOfNumbers = (
Gen.Choose(int.MinValue, int.MaxValue).NonEmptyListOf().ToArbitrary()
);
return Prop.ForAll(generatorOfListOfNumbers,numbers =>
{
var sortedNumbers = ListSorter.Sort(numbers);
IsOrdered(sortedNumbers).Should().BeTrue();
}
);
}
static bool IsOrdered(List<int> numbers)
{
if (numbers.Count >= 2)
{
for (int i = 1; i < numbers.Count; i++)
{
if (numbers[i - 1] > numbers[i])
{
return false;
}
}
}
return true;
}
[Property]
public Property ASortedListAndUnsortedListHasBothTheSameSize()
{
var generatorOfListOfNumbers = (
Gen.Choose(int.MinValue, int.MaxValue).NonEmptyListOf().ToArbitrary()
);
return Prop.ForAll(generatorOfListOfNumbers,numbers =>
{
var sortedNumbers = ListSorter.Sort(numbers);
sortedNumbers.Count.Should().Be(numbers.Count);
}
);
}
[Property]
public Property NoNumbersAreAdded()
{
var generatorOfListOfNumbers = (
Gen.Choose(int.MinValue, int.MaxValue).NonEmptyListOf().ToArbitrary()
);
return Prop.ForAll(generatorOfListOfNumbers,numbers =>
{
var sortedNumbers = ListSorter.Sort(numbers);
sortedNumbers.All(numbers.Contains).Should().BeTrue();
}
);
}
[Property]
public Property NoNumbersAreDeleted()
{
var generatorOfListOfNumbers = (
Gen.Choose(int.MinValue, int.MaxValue).NonEmptyListOf().ToArbitrary()
);
return Prop.ForAll(generatorOfListOfNumbers,numbers =>
{
var sortedNumbers = ListSorter.Sort(numbers);
numbers.All(sortedNumbers.Contains).Should().BeTrue();
}
);
}
}
namespace Kata.biggest_number;
public class ListSorter
{
public static List<int> Sort(List<int> numbers)
{
numbers.Sort();
return numbers;
}
}
Consiste en identificar una secuencia reversible de acciones que se puedan ensamblar entre sí. Con esto, si una acción es la contraria de la otra, al aplicar ambas operaciones se debería obtener la entrada inicial como salida final. Si se comprueba esto, significa que todas las partes encajan bien. Cuando buscamos invariantes, buscar simetrías permite crear conexiones con los invariantes; de esta manera, con una alta simplicidad se puede lograr una gran cobertura. Un ejemplo simple es el típico algoritmo de codificación-decodificación binaria.
namespace Kata.Tests;
using FluentAssertions;
using FsCheck;
using FsCheck.Fluent;
using FsCheck.Xunit;
public class BinariesShould
{
[Property]
public Property SymmetricEncodingDecoding()
{
var generatorOfListOfNumbers = (
Gen.Choose(int.MinValue, int.MaxValue).NonEmptyListOf().ToArbitrary()
);
return Prop.ForAll(generatorOfListOfNumbers,numbers =>
{
var encodeNumbers = BinaryEncoder.Encode(numbers);
var decodeNumbers = BinaryDecoder.Decode(encodeNumbers);
decodeNumbers.Should().BeEquivalentTo(numbers);
}
);
}
}
using System.Collections;
namespace Kata.Tests;
public class BinaryEncoder
{
public static List<BitArray> Encode(List<int> numbers)
{
var encodedNumbers = new List<BitArray>();
foreach (var number in numbers)
{
encodedNumbers.Add(new BitArray(new[] {number}));
}
return encodedNumbers;
}
}
using System.Collections;
namespace Kata.Tests;
public class BinaryDecoder
{
public static List<int> Decode(List<BitArray> binaryCode)
{
var decodedNumbers = new List<int>();
foreach (var bitArray in binaryCode)
{
var number = 0;
for (var i = 0; i < bitArray.Length; i++)
{
if (bitArray[i])
{
number += (int) Math.Pow(2, i);
}
}
decodedNumbers.Add(number);
}
return decodedNumbers;
}
}
¿Quieres más? te invitamos a suscribirte a nuestro boletín para avisarte cada vez que recopilemos contenido de calidad que compartir.
Si disfrutas leyendo nuestro blog, ¿imaginas lo divertido que sería trabajar con nosotros? ¿te gustaría?
Pero espera 🖐 que tenemos un conflicto interno. A nosotros las newsletter nos parecen 💩👎👹 Por eso hemos creado la LEAN LISTA, la primera lista zen, disfrutona y que suena a rock y reggaeton del sector de la programación. Todos hemos recibido newsletters por encima de nuestras posibilidades 😅 por eso este es el compromiso de la Lean Lista
