

Data quality is probably the biggest concern in any organization that works with data to build models with artificial intelligence, use it for business intelligence, or generate data automatically for some use cases. In this sense, it is required to create a network of validations around the output dataset of any process in the data pipeline. The first approach is to perform a manual data analysis with notebooks in order to detect defects. However, this is super inefficient in terms of time usage (each time the dataset is generated, it needs to be validated). Although when the generation is well spaced with another one, maybe it could be enough. But normally, that is not the case, so in data engineering, we try to automate this and add it to the data pipeline to run all-in-one.
We could do it by creating assertions in a notebook and also generate a report. The problem with this is that we cannot easily maintain it when validations become more complex or the dataset changes slightly. So, what are the alternatives? We could use some of the tools that are mentioned here, but SODA is probably the best one because it uses a simple language declaration to check with SQL when we need complex assertions. It is open-source and it will introduce the GPT model to create validations with natural language, and it allows us to use many different data sources. Therefore, this is the tool that I will use to develop checks for dataset outputs. But, How can we be sure that the validations are accurate?
Here is where Test-Driven Development (TDD) will help us achieve these requirements.
TDD is an approach to develop software with testing as the first step, so how can we apply this with SODA Check in a YAML file? What we have to do is create a test for each defect we want to validate in the output dataset beforehand, in other words, declare how we are going to validate that dataset. My proposal is to use the following structure in the tests:
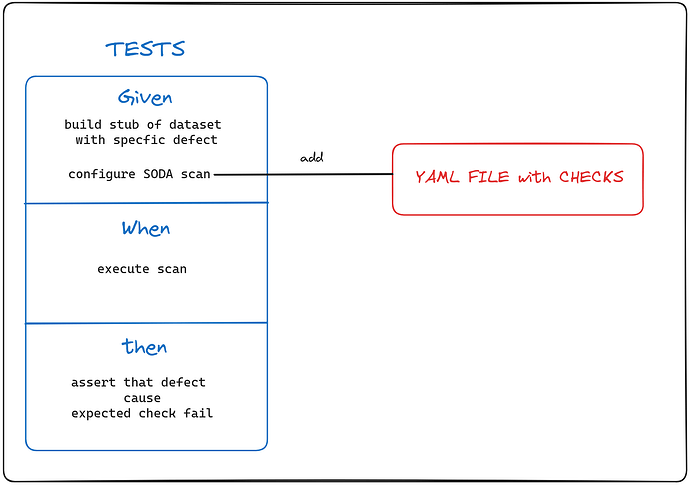
In the GIVEN part, we should build a stub at runtime with the specific defect that we want to detect, but in the other dimensions it should be correct. Also, we have to configure the scanner of SODA (at this point, we link the YAML file that we want to test).
In the WHEN part, we should just execute the scan (the API that runs the checks).
In the THEN part, we should verify that there are only the check failures that we tried to cause.
In the verification part is the key, we are going to use the following:
def checks_failures_found_by(scan: Scan):
return list(map(lambda check: check.name, scan.get_checks_fail()))
def test_foo(self):
#GIVEN
...
#WHEN
...
#THEN
assert_that(checks_failures_found_by(scan)).contains_only(
"Some check you want to declare"
)
In this sense, our observation point will be the ‘Scan’ object, which provides us an API to retrieve the check failures produced during execution.
Once we have applied this approach, it is important to think about the benefits of this approach: TDD will provide us with a set of tests that ensure the YAML file with checks behaves as expected and that the implementation is simple. Let’s delve into the statement “checks will behave as we expect.” This not only verifies that YAML works, but also provides us with tests that will fail for a specific reason, offering fast feedback during development and maintenance. Additionally, the tests will explicitly show how we validate the dataset, as we will carefully name them. In this sense, they will serve as live documentation of our dataset validation process (although the YAML file is expressive, it could be misleading). Lastly, we have declared how we are going to validate independently of the implementation. In other words, we have opened up new possibilities to improve the checks in the future, as there are several ways to assess different dimensions of data quality. At this point, you may have grasped the idea, but it is crucial to see how this can become a reality from a practical perspective. Let’s move on to a practical example.
In order to show you how this approach works with SODA, I will develop a use case explained in this repo. The important thing is how to face this efficiently. You might be thinking, “How will I provide a dataset for tests?” “Do I need to create tests with I/O?” “Will tests be slow?” “If my data will be validated in some data platform or database, how will I be able to handle this situation?” I will answer with two words: stubs and pandas. At the end, we want to validate that check implementations work as we expected, not the connection with the data source, and the checks are independent of the data source. So, we could provide a more accessible source of data for our purpose, such as pandas, because we could create a stub of the dataset output at runtime and pass it to the scanner of SODA to apply the check over this. In this way, we would resolve all issues with this approach, as we can see in the following video (it is in Spanish, but you can activate subtitles):
This is the repo where the example is:
Contribute to Marius9595/soda-checks-development-example-with-tdd development by creating an account on GitHub.
TDD provides us:
Thanks Kevin Hierro to show me things like the Stub builder that improves the tests! Also Cristian Suarez to discuss with me about this approach, and Lean Mind to give me the testing perspective that allowed me to develop this.
Do you want more? We invite you to subscribe to our newsletter to get the most relevan articles.
If you enjoy reading our blog, could you imagine how much fun it would be to work with us? let's do it!
But wait a second 🖐 we've got a conflict here. Newsletters are often 💩👎👹 to us. That's why we've created the LEAN LIST, the first zen, enjoyable, rocker, and reggaetoner list of the IT industry. We've all subscribed to newsletters beyond our limits 😅 so we are serious about this.

