Arquitectura de referencia: front de chat + backend con contexto + LC4j
24-04-2026
Diseñar una arquitectura funcional y lista para producción con LangChain4j no requiere docenas de microservicios. Con una base bien estructurada —frontend, API, ruteo, herramientas y agentes— puedes poner en marcha asistentes conversacionales eficientes, escalables y trazables. Esta guía resume los componentes esenciales, su flujo y consideraciones clave para llevarlos a producción.
1. Componentes principales
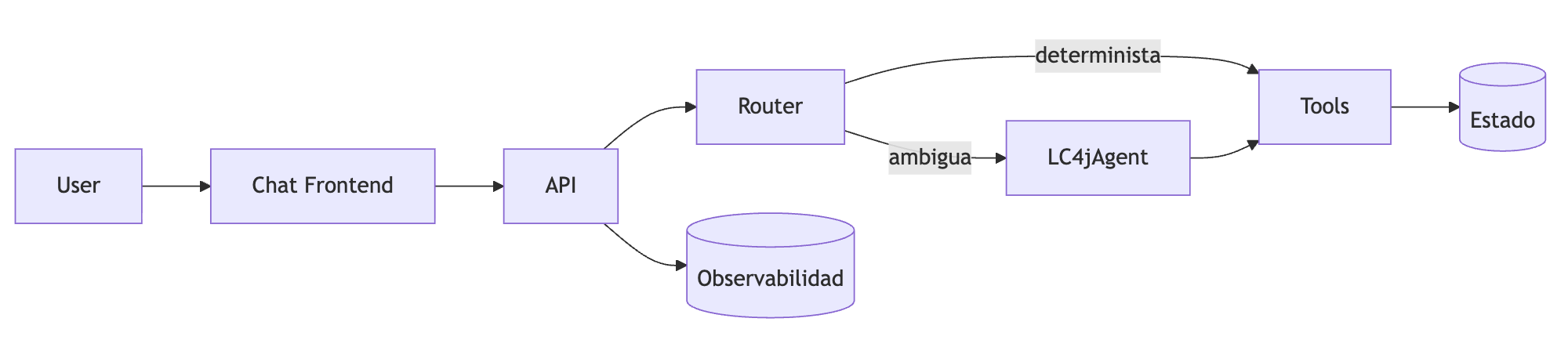
- Frontend de chat: Cliente web o móvil que envía mensajes y muestra respuestas.
- API: Punto de entrada REST, típicamente en
/v1/conversations/{id}/messages. - Router: Decide si la petición se resuelve con lógica determinista o se deriva al agente.
- Tools: Funciones externas accesibles vía código.
- LangChain4j: Motor principal que coordina agentes, herramientas y flujos.
- Almacenes: Bases de datos para estado estructurado, historial, logs y métricas.
2. Seguridad en producción
Toda arquitectura de este tipo debe contemplar:
- Autenticación y autorización.
- Rate limiting por IP o usuario.
- Higiene de PII: detección, anonimización, protección.
3. Flujo de mensaje y contratos
Cada mensaje:
- Entra por el API con
conversationId,userIdeinputText. - El router detecta intención y ruta adecuada.
- Se consulta o actualiza estado estructurado.
- Se generan o calculan salidas.
- El backend post-procesa y devuelve la respuesta.
Todos los intercambios deben seguir contratos de entrada/salida bien definidos (ej. JSON schema).
4. Memoria, estado y persistencia
- Ventana de conversación: contexto reciente.
- Resumen incremental: para sesiones largas.
- Estado estructurado: claves de preferencia, historial lógico, flags.
- Base de datos: persistencia de todo lo anterior con versionado.
5. Operación y costes
- Observabilidad: logs, métricas, alertas por capa (API, router, agent, tools).
- SLAs por capa (tiempo de respuesta máximo, % de errores).
- Presupuesto de tokens y latencias por tipo de ruta.
Tabla de responsabilidades por capa
| Capa | Rol | Entrada | Salida | SLA esperado | Riesgos principales |
|---|---|---|---|---|---|
| Frontend | UI/UX | input del usuario | respuesta | <200 ms render | UX pobre, timeouts |
| API | Entrada/salida | mensaje, metadatos | JSON estructurado | <300 ms | DDoS, fallos auth |
| Router | Routing lógico | input + intención | ruta | <50 ms | clasificador incorrecto |
| Tools | Funciones de negocio | parámetros | respuesta determinista | <500 ms | errores lógicos |
| LC4jAgent | Razonamiento y coordinación | contexto, tools | texto | <1.5 s | loops, desviaciones |
| StateDB | Persistencia | estado y contexto | estado actualizado | variable | pérdida de datos, incoherencia |
| Metrics/Logs | Observabilidad | eventos | dashboards/alertas | realtime | falta de visibilidad |
Checklist técnico
- Contratos I/O estrictos (schemas).
- Gestión de claves de conversación y usuario.
- Políticas de prompts claras y auditables.
- Límites por pasos, tokens y tools.
- Logging estructurado.
Preguntas frecuentes
- ¿Cómo aislar dominios o clientes distintos?
- Separando contextos (bases de datos, claves, memoria) y configuraciones (tools, policies) por tenant.
- ¿Es compatible con entornos multi-tenant?
- Sí, si la arquitectura soporta aislamiento de memoria, estado y configuración por instancia.
Conclusión
Una arquitectura sencilla pero bien definida permite lanzar asistentes productivos sin comprometer control ni escalabilidad. En Lean Mind acompañamos a nuestros clientes en la definición e implementación de este tipo de sistemas, desde el primer mensaje hasta el monitoreo en producción.
