RAG en producción: retriever ≠ razonamiento (y por qué te importa)
25-02-2026
El patrón RAG (Retrieval-Augmented Generation) es uno de los más utilizados para mejorar la precisión de las respuestas generadas por modelos LLM. Sin embargo, confundir la recuperación de contexto con el razonamiento del modelo es un error común que puede comprometer la calidad, el coste y la auditabilidad del sistema. Entender esta separación es clave para escalar soluciones basadas en LangChain4j de forma efectiva.
1. Anatomía de RAG
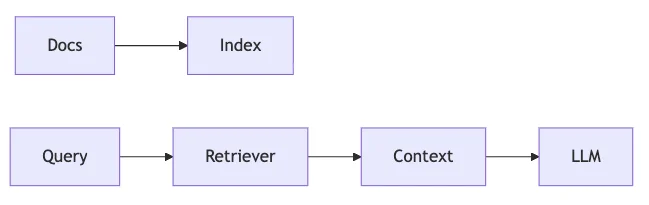
Un sistema RAG consta de varias etapas bien diferenciadas:
- Ingesta: Preprocesamiento y carga de documentos.
- Indexado: Conversión a embeddings y almacenamiento en un vector store.
- Retriever: Consulta el índice para extraer pasajes relevantes.
- Generación: El LLM recibe el contexto y produce una respuesta.
2. Métricas de recuperación ≠ calidad de respuesta
Es común evaluar un sistema solo por cómo responde el modelo, pero en RAG, el retriever tiene su propio conjunto de métricas:
- Recall@k: ¿Está el documento correcto entre los k recuperados?
- Precision@k: ¿Cuántos de los k son realmente relevantes?
Puedes tener buena recuperación, pero una respuesta deficiente si el LLM no integra bien el contexto o, al revés, una respuesta afortunada pese a un contexto mediocre.
3. Controles finos del retriever
Para evitar problemas de ruido o ambigüedad, es fundamental configurar:
- Número de pasajes (k): Cuántos fragmentos se pasan al modelo.
- Filtros: Por tipo, fecha, fuente o score.
- Rankers: Reordenar los resultados antes de pasarlos al prompt.
Pasa solo lo necesario al prompt. El exceso de contexto degrada.
4. Versionado y rollback de índices
Como cualquier componente crítico, el índice debe:
- Tener versiones auditables.
- Permitir rollback ante cambios de contenido, embeddings o estrategia de chunking.
Esto es clave para entornos regulados o productos sensibles a cambios.
5. Observabilidad específica
En producción, debes saber:
- Qué documentos se usaron para cada respuesta.
- Qué score tuvo cada uno.
- Si falló la recuperación (por ejemplo,
recall@k = 0).
Registrar esta información permite explicar errores, afinar el sistema y justificar decisiones ante usuarios o auditores.
Tabla de control de versión de índice
| Versión índice | N docs | k vecinos | Latencia | Recall@k | Incidencias |
|---|---|---|---|---|---|
| v1.0 | 5000 | 5 | 850 ms | 0.72 | - |
| v1.1 | 7200 | 4 | 910 ms | 0.81 | docs antiguos ignorados |
Checklist técnico
- Dataset gold etiquetado por humanos.
- Límite de contexto claro (tokens o docs).
- Política de refresco del índice (frecuencia, triggers).
- Capacidad de rollback segura.
Preguntas frecuentes
-
¿Cuándo usar búsqueda híbrida (texto + vectorial)?
- Cuando el dominio tiene mucho contenido exacto (fechas, códigos, nombres) junto con semántica difusa.
-
¿Qué pasa si cambia el dominio del contenido?
- Es necesario reentrenar embeddings, reindexar y posiblemente ajustar filtros y rankers.
Conclusión
RAG no es solo una técnica, es una arquitectura que requiere control fino en cada fase. Separar recuperación de razonamiento permite evaluar, auditar y mejorar cada componente de forma independiente.
