Optimización de query al crear índices ⏱ & Tips de DataGrip
22-02-2024
Herramientas utilizadas:

DataGrip - JetBrains
Versión utilizada: 2021.3.1
macOS 11.6
Hay ocasiones en las que trabajamos con muchos datos, y realizar una query hace que se demore mucho porque va realizando una búsqueda literal, en la que va mirando en cada fila buscando que las condiciones coincidan. Así es como recorrería por los datos, si quiero encontrar algún cups en específico:
Aquí si analizamos con un EXECUTION PLAN, podríamos ver cuánto le cuesta encontrar los datos en cuestión. Con Datagrip es pinchar con “Clic derecho sobre la query > Explain Plan > Explain Analyse”
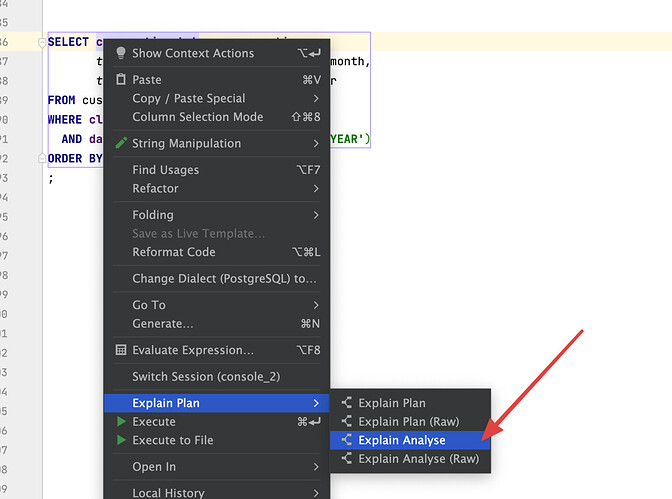
Esto ayuda a identificar el Total Cost, que es como el coste en recursos (CPU e I/O) que tiene esa query, (notemos que es elevado). Por otro lado también vemos que se toma unos 414 ms.
Esto evidentemente con un usuario no se suele notar, pero cuando ya hablamos de 100 es otra cosa.

Una manera de solucionar esto es insertando un índice, con ello conseguiremos optimizar la query de manera que a la hora de buscar, irá buscando y descartando filas, haciendo que tarde menos la búsqueda.
👈🏼 - 🔍 Abre esto para entender un poco cómo sería la búsqueda con el índice
Sería algo así en una lista de ciudades:
Barcelona
Madrid
Ámsterdam
Doha
Beijing
Ciudad del Cabo
Santa Cruz de Tenerife
Cartagena
Doha
Santa Cruz de la Palma
Florencia
Santa Cruz de Tenerife
Santa Cruz de la Palma
Las ordenamos en orden alfabético:
Amsterdam,
Barcelona,
Beijing,
Cartagena,
Ciudad del Cabo,
Doha,
Doha,
Florencia,
Madrid,
Santa Cruz de Tenerife,
Santa Cruz de Tenerife,
Santa Cruz de la Palma,
Santa Cruz de la Palma
Y ahora le decimos que queremos encontrar cosas con "Santa Cruz de Tenerife". Al ver que hasta la fila 10 nada empieza por la “s” salta hasta ahí y hace un descarte:
Santa Cruz de Tenerife,
Santa Cruz de Tenerife,
Santa Cruz de la Palma,
Santa Cruz de la Palma
Luego solo tendrá que comparar hasta llegar a la "T" donde encontraría el resto.
Siguiendo con este enfoque creamos el índice:
CREATE INDEX invoices_cups_inx ON invoices(cups)
Los índices son únicos y no pueden repetirse en toda la base de datos, además de esto, sólo pertenecen a la tabla mencionada. Con esto podríamos reducir hasta un 90% el tiempo que se toma en la consulta.
💡PD: A la hora de elegir el campo sobre el que hacer el índice, hay que ver la variabilidad del campo. Si cambia poco está perfecto para poder hacerlo. Si cambia mucho no merece la pena.
Volvemos a hacer el EXECUTION PLAN para ver los nuevos resultados:

Es abrumador el tiempo que se toma ahora 🤩. De prácticamente 7 ms VS 414 ms que se tomaba al principio, hemos mejorado un 6300% los tiempos de esta query
Conclusión
Parte buena
Ganamos en agilidad y optimización de recursos.
Parte mala
Esto penaliza los inserts, porque cada vez que se inserta algo, tiene que reconstruir el índice. Para estos casos sería conveniente tirar por otro enfoque, como por ejemplo, hacer una tabla materializada o una proyección según lo que he podido leer “por ahí”, pero es algo que no he tocado todavía 👀.
Recursos
Conocer más opciones de Datagrip en este video
Curso para entender el coste de las queries
Cualquier cosita que veáis interesante a destacar sería genial poder debatirla. Es un mundo que sigo investigando (el de las bases de datos) y sé que me queda un vasto mundo por conocer 😂.
