De lo invisible a lo visible, descubre el poder de la telemetría y la observabilidad
09-05-2025
¿Alguna vez has sentido que desarrollas aplicaciones a ciegas, confiando en pruebas manuales y en los reportes de los usuarios para solucionar problemas? ¿Te imaginas que puedas tener una visión clara y en tiempo real de lo que sucede dentro de tu sistema, desde el tiempo de respuesta de un microservicio hasta un cuello de botella en un servicio externo?Pues tengo que contarte que este poder existe, y se conoce como telemetría y observabilidad.
El valor de la telemetría y la observabilidad: Una visión personal
Antes de entrar en materia sobre lo que son, me gustaría compartir contigo por qué considero necesario incluir estos términos en nuestro camino.
Hace un tiempo, acudí a una charla de Cloud Native en Sevilla, donde nos hablaban de los nuevos usos en herramientas de CD/CI integradas con OpenTelemetry. Al principio, veía un atisbo de dudas e incógnitas, pero nada más buscar los dos grandes titanes mencionados, descubrí un imprescindible a conocer en mi carrera como desarrolladora.
Para que entiendas el porqué, me gustaría que imaginaras una aplicación con un tráfico de usuarios inmenso, la cual además usa diferentes microservicios.
Por ejemplo, imagina que tu aplicación experimenta un aumento en el tiempo de carga de las páginas. Aquí es donde la telemetría se convierte en tu mejor aliada: puedes recopilar datos de las métricas, como son el tiempo de respuesta de cada microservicio y el uso de recursos en cada uno de ellos.
Por otro lado, con la observabilidad, puedes analizar esos datos en conjunto. Supongamos que detectas que uno de tus microservicios relacionados con el pago, últimamente es demasiado lento. Mediante el análisis de las trazas, puedes seguir el flujo de una solicitud desde que el usuario hace clic en “pagar” hasta que se completa la transacción. Esto hace que te percates de que el problema radica en un servicio de terceros que estás utilizando para procesar pagos.
¿Imaginas tener que ir página por página, calculando los tiempos de espera, así como por cada microservicio, para detectar cuál es el que falla cuando resulta que es uno de terceros? Sin telemetría, tendríamos que confiar en testeo manuales y en la experiencia de los usuarios para identificar el problema. Además, la falta de visibilidad del problema, hace que los desarrolladores nos sintamos a ciegas. Y sin la ayuda de la observabilidad, cada problema se convierte en una caza del tesoro, y el riesgo de que un problema crítico pase desapercibido aumenta exponencialmente, haciendo que nuestros usuarios puedan tener una mala experiencia y que además, no seamos conscientes de ello.
En mi trayectoria como desarrolladora, intento cumplir con dos principios fundamentales: ofrecer un excelente servicio a los usuarios y garantizar el funcionamiento óptimo de mi aplicación. Y es gracias a la telemetría y la observabilidad, que puedo cumplir mis máximas.
Caso práctico
Con la idea de hacer más fácil la comprensión de los conceptos, he optado por incluir un caso práctico simple y visual que nos dé una visión más amplia. Para ello, he utilizado una aplicación de ejemplo con Spring Boot ya dockerizada para que podamos levantar en nuestro local fácilmente y lanzar algunas peticiones de manera que podamos ser capaces de observar qué está ocurriendo.
De las herramientas más conocidas que existen actualmente nos encontramos con Datadog, Elastic y New Relic.
¡Se abren las puertas!: Petclinic como ejemplo
Una vez ejecutada nuestra aplicación en nuestro local, debemos seguir la guía proporcionada por la herramienta que queremos utilizar. En mi caso, he utilizado New Relic porque no tiene un periodo free trial, sino que nos permite utilizar una cantidad limitada de gigas para ingestar datos.
En las dos siguientes imágenes, podemos observar nuestra aplicación en Spring Boot dentro de la plataforma de New Relic. Para ello, hemos tenido que seguir los pasos e inyectar su agente.
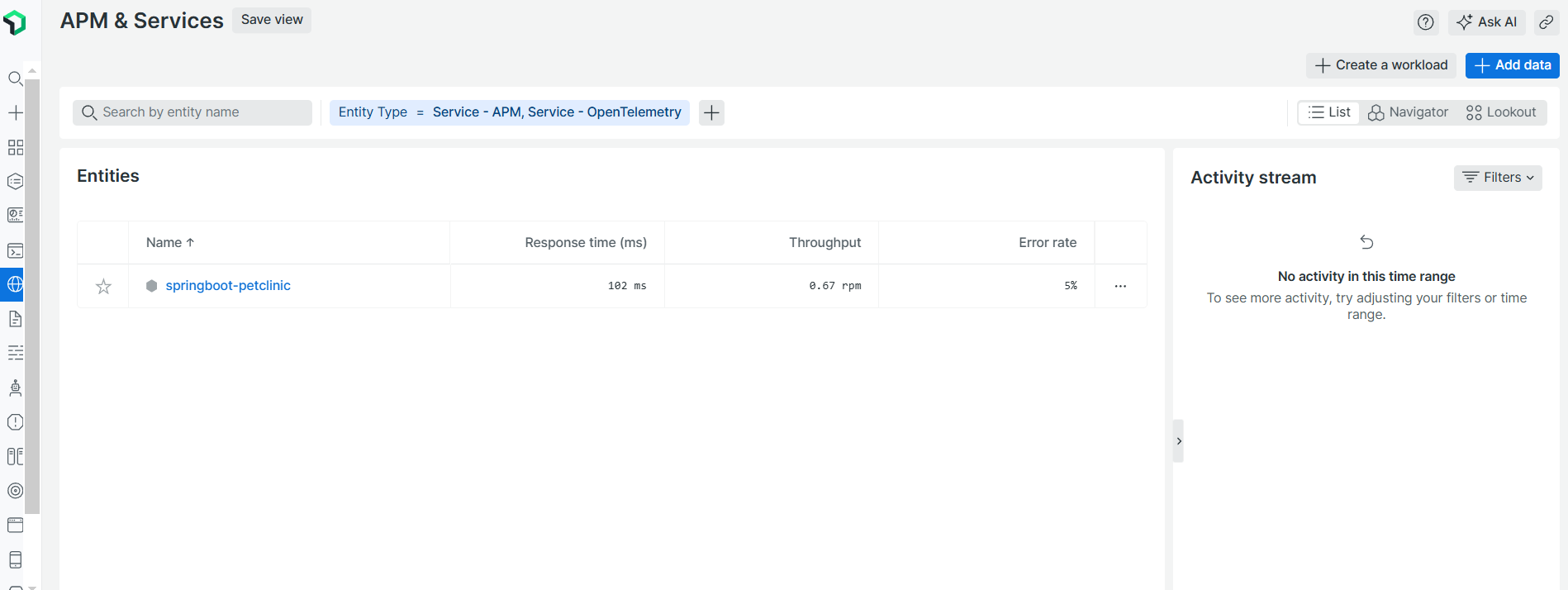
Una vez vistas estas imágenes, podemos decir que un agente es un pequeño componente de software que se instala junto a tu aplicación y actúa como un “puente” entre esta y la herramienta de observabilidad que estés usando (en este caso, New Relic). Su función es recopilar datos clave de tu aplicación, como métricas de rendimiento, trazas de las peticiones y registros de eventos (logs), y enviarlos a la plataforma de observabilidad para que puedas visualizarlos y analizarlos fácilmente.
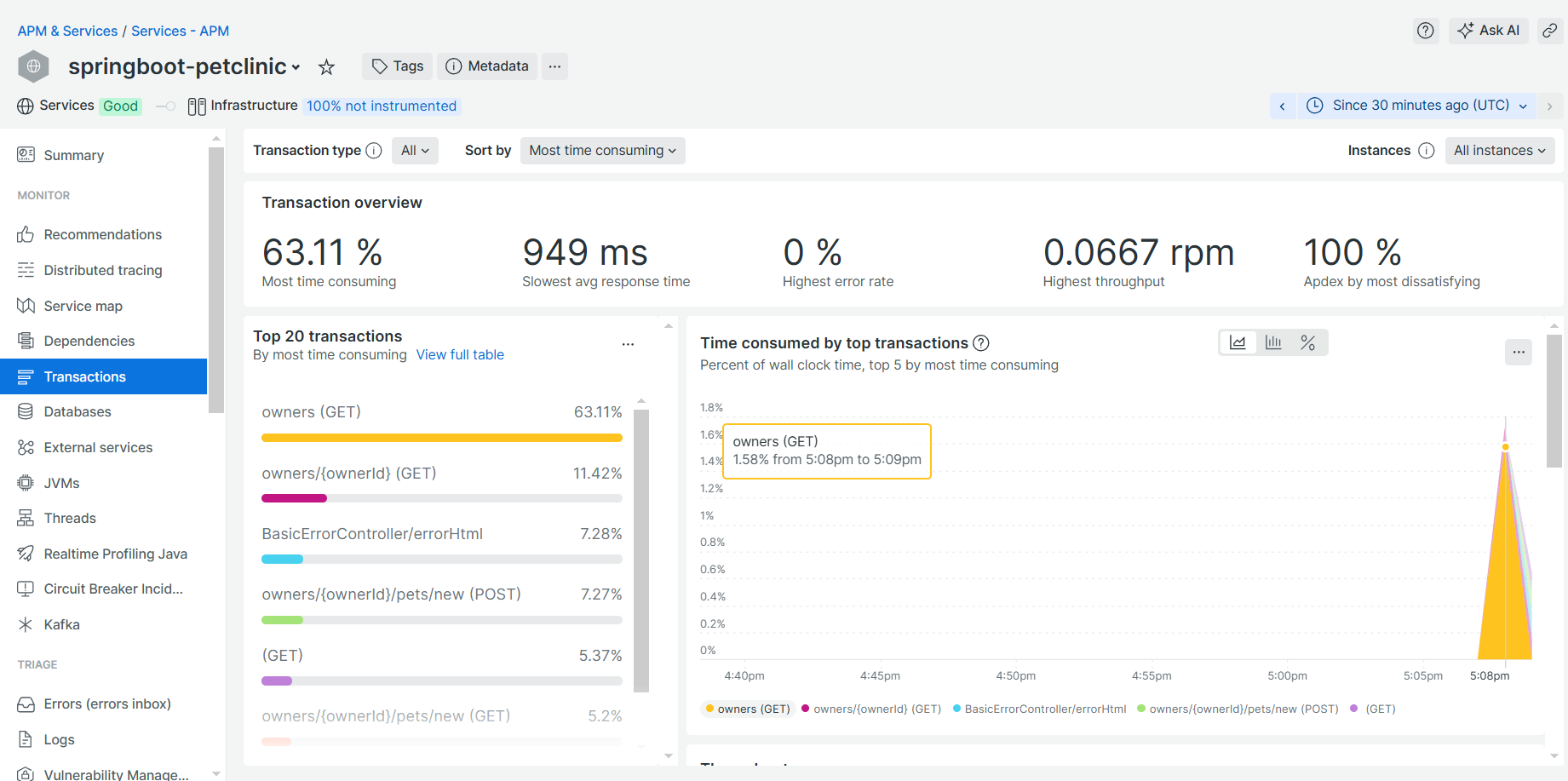
Una vez establecido nuestro puente, simplemente nos queda trastear por la aplicación para generar muchas peticiones, de forma que desde nuestra herramienta de observabilidad, podemos ver visualmente datos interesantes, como por ejemplo las llamadas más habituales junto a sus métodos cómo podemos ver en la siguiente imagen.
Features extras para observar nuestro sistema
Alertas
Una de las mayores utilidades que he encontrado para mantener nuestro sistema a alerta (nunca mejor dicho) es la posibilidad de crear dichas de una forma personalizada.
Cualquier herramienta de observabilidad nos permite añadir alertas cuando, por ejemplo, detectamos un pico de latencia muy alto en nuestras peticiones. Un ejemplo práctico sería la posibilidad de configurar una alerta en el endpoint GET que mencionamos anteriormente —ya que, como podemos observar, es el más utilizado y, por ende, el que más queremos monitorear—, de esta forma nos permitiría detectar problemas de latencia antes de que alcancen su pico máximo. Esto ayudaría a prevenir la pérdida de usuarios y nos permitiría tomar acciones proactivas.
En resumen, la pérdida de usuarios debido a la lentitud de la aplicación al procesar peticiones sería algo evitable, ya que nuestro sistema estaría preparado para mitigar muchos de estos riesgos de forma anticipada.
Custom alerts
Aunque el ejemplo presentado está pensado para una aplicación Backend, es importante destacar que podríamos aplicar observabilidad también en nuestro Frontend. Por ejemplo, podríamos monitorear los botones de redirección hacia otras páginas y analizar cuantas veces se han pulsado. Esto nos permitiría detectar patrones de uso o problemas de usabilidad en tiempo real, optimizando la experiencia del usuario.
Conclusiones finales
A través de este artículo, hemos visto cómo un agente de observabilidad, como el de New Relic, nos permite recolectar y visualizar métricas, trazas y logs que son vitales para entender el rendimiento de nuestros sistemas. Con esta información, no solo podemos identificar rápidamente los puntos de fricción en nuestras aplicaciones, sino que también estamos mejor equipados para tomar decisiones informadas y responder a incidentes antes de que impacten a los usuarios.
En resumen, adoptar la observabilidad y la telemetría como parte de nuestro proceso de desarrollo nos otorga el poder de ver y analizar lo que sucede en tiempo real, facilitando el monitoreo y la mejora continua de nuestras aplicaciones.
¡Espero que este artículo te haya despertado la curiosidad! 
Glosario
Y por si te has quedado con alguna duda, aquí te dejo un pequeño glosario con los principales conceptos que hemos ido descubriendo en este artículo.
-
Telemetría: Proceso de recopilación, transmisión y análisis de datos sobre el rendimiento y el comportamiento de un sistema en tiempo real, fundamental para habilitar la observabilidad.
-
OpenTelemetry: Conjunto de herramientas, APIs y SDKs estándar que permiten recopilar, procesar y exportar telemetría (métricas, trazas y logs) de aplicaciones para integrarlas con plataformas de monitoreo.
-
Observabilidad: Capacidad de analizar el estado interno de un sistema basándose en los datos generados por el mismo, como métricas, trazas y logs. Facilita la identificación y resolución de problemas.
-
Logs: Entradas generadas automáticamente por una aplicación que contienen información sobre eventos, errores y procesos, útiles para diagnosticar problemas y analizar el comportamiento del sistema.
-
Métricas: Datos numéricos que reflejan el rendimiento de una aplicación o sistema, como el tiempo de respuesta, uso de CPU, memoria o cantidad de solicitudes procesadas por segundo.
-
Alertas: Mecanismos configurables en herramientas de observabilidad que notifican a los desarrolladores sobre condiciones específicas, como picos de latencia o errores frecuentes, permitiendo tomar acciones proactivas antes de que impacten al usuario.
-
Trazas: Rutas completas que sigue una solicitud a través de una aplicación o sistema. Permiten entender cómo se procesan las solicitudes y ayudan a identificar cuellos de botella o fallos.
-
Agente: Componente de software que se instala junto a una aplicación para recopilar métricas, trazas y logs. Actúa como un puente entre la aplicación y una herramienta de observabilidad, enviando datos clave a la plataforma para su análisis y visualización.
